Media Supply Chain Automated.
How we rebuilt the content supply chain for a Hollywood media-processing lab as a cloud-native pipeline on AWS — taking it from manual, on-prem, per-source workflows to a platform where 95% of orders process automatically, from ingest to delivery.
Every title, delivery-ready in hours — not days
The lab needed to scale media processing without scaling the manual effort behind it.
A Hollywood-based media-processing lab — the content-operations arm of a global in-flight entertainment (IFE) provider — asked us to rebuild the supply chain it used to turn studio content into airline-ready deliverables.
IFE content arrives from a long tail of studios and distributors, in every conceivable format, and has to be verified, processed, catalogued, and delivered to a wide range of airline and system specifications. The lab handled all of it — but the process had grown up as a patchwork rather than a platform.
The brief was not a like-for-like upgrade. The lab needed to scale throughput and add reliability without scaling the manual effort behind every order.
Almost every source and every target system demanded its own workflow.
Files were received, verified, and processed largely by hand, on-premise, using a collection of desktop tools. Finished assets were catalogued on local servers, then pushed through delivery using command-line steps, PowerShell scripts, and complex, bespoke processes — and almost every source and every target system demanded its own workflow.
Throughput was capped by people and local machines rather than by demand, work ran in roughly monthly cycles, and institutional knowledge lived in scripts and individual operators rather than in a system.
A compounding problem was duplication: because files were poorly catalogued, the same titles were re-acquired and re-processed again and again, so each order effectively started from scratch — and finished work often went out only days ahead of its deadline.
We took ownership of every stage, from ingest to delivery.
We designed and built a new platform from the ground up on AWS — microservices, serverless, AWS Step Functions, and Amazon EventBridge — that takes ownership of every stage of the supply chain.
Each stage that used to be a manual handoff became an automated, observable step in an orchestrated workflow. The aim was not to lift the old process into the cloud, but to redesign it so that people were left only with the decisions that genuinely need human judgment.
The platform is built as a set of microservices, each owning a business capability — ingest, file processing and QC, the content catalogue, and orders — behind a single web application that composes them into the views operators actually use. A shared core handles identity and access, the secure compute where files are processed, and search, while supporting services cover monitoring and deployment automation.
Files land in secure cloud storage that still looks like a network drive.
Files reach the platform three ways: a direct Aspera integration; dedicated, isolated buckets provisioned per supplier (an "originator"), to which external parties get scoped key- or role-based access to push files directly; and a managed upload path — the most common — where, using AWS Storage Gateway, cloud storage is mounted as an ordinary network drive inside virtual machines in a private subnet.
Operators and existing tools work against familiar drives, while the files themselves live in secure, durable cloud storage. Whichever route a file takes, it converges on the same ingest queue. The platform can also browse the lab's cloud archive, part of moving content off on-premise servers.
Correctness is checked automatically, before anything moves downstream.
Each file that lands in the secure store triggers a type-specific Step Functions state machine — one for video, one for audio, one for subtitles. For video, the pipeline extracts technical metadata (via ffprobe), loudness-normalises the audio, and uses AWS MediaConvert to produce two derivatives: an H.265 master used downstream for orders, and a fragmented, watermarked, DRM-protected H.264 proxy streamed in the web app for review.
Amazon Rekognition then analyses the video and flags defects such as black frames, colour bars, and where subtitles begin and end — so a reviewer no longer has to watch a title end to end. Longer-running steps run as containerised ECS tasks rather than time-limited functions, and each step is independently logged.
A QC team, separate from the team that ingests files, then confirms technical correctness: that audio matches video and subtitles align with the picture.
One master, every format the downstream needs.
The platform produces the reusable building blocks consumed downstream. Audio is loudness-normalised to specification, an H.265 master is generated, and subtitles are converted across the formats different airlines require.
A single incoming SCC or SRT file is expanded into the SRT, VTT, ZIP, and DVB variants an order may call for — so a deliverable can be packaged on demand rather than maintaining a bespoke workflow per destination.
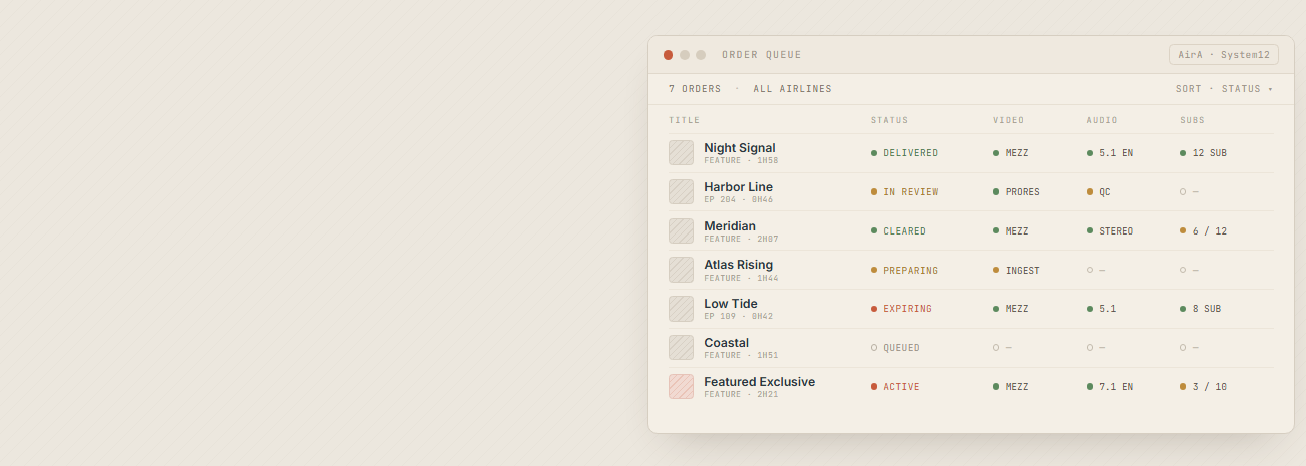
Cataloguing, order fulfilment, and delivery became one automated flow.
A raw file as received is a "master"; once a reviewer links it to a specific title and version it becomes an "asset" — ready to fulfil orders. Video, audio tracks, and subtitles belonging to the same version are grouped as conforming assets, verified to be in sync, and a uniqueness model prevents the duplicate masters that plagued the old process. As the catalogue fills it becomes, in effect, an inventory: a title already catalogued is reused across airlines and encodes instead of being re-acquired.
An order arrives as a request — most often synced from the provider's upstream system — and the operator routes it to one of two workflows the platform manages side by side: cloud or on-premise. Cloud is the default and the goal, being automatic, cheaper, and faster, with on-premise reserved for the minority of files the cloud pipeline can't yet handle. Once every required asset is present, processing starts automatically: the platform prepares video and audio, muxes them into the output file, and handles subtitles. What each airline and onboard system needs — output format (MPEG-1, MPEG-2, or MPEG-4), mux and subtitle handling, delivery method, and the agreed output file name — is captured once in a per-airline configuration layer and applied automatically thereafter.
Completed deliverables are dispatched automatically — via Signiant, Aspera, or SmartJog, chosen per target — to the integrators that load content onto the aircraft, and the platform reports order status and delivery back to the lab's upstream system, keeping the whole pipeline visible end to end.
Built to studio and enterprise standards.
The platform was engineered to studio and enterprise standards, not just to function. Security was designed in from the start — a private VPC, private-only traffic, and encryption at rest. The completed system passed a three-stage security review covering an infrastructure security scan, penetration testing, and full documentation.
Operations are backed by Datadog observability and active support. Every service has its own pipeline that deploys application code and infrastructure together — a single service may stand up dozens of cloud resources — and because the entire platform is defined as infrastructure-as-code, full disaster recovery is repeatable and reliable rather than aspirational. All platform operations are audited.
95% of orders now process themselves, and delivery dropped from days to hours.
Today, 95% of orders are processed fully automatically in the cloud, at a scale of roughly 5,000–6,000 orders every month.
The clearest change is where people sit in the workflow. Before, operators touched every step — ingest, encode, QC, format, mux, and deliver. Now their role collapses to two checkpoints: verifying the original file on the way in, and the finished deliverable on the way out. Everything in between runs hands-off.
Speed changed just as sharply. Orders that once ran in roughly monthly cycles are now fulfilled on demand: when the required assets are already catalogued, an order can be processed in minutes; where the old process delivered only in the final three to five days before a title's due date, the platform now ships within hours of receiving the order and its master.
Quality improved alongside speed: with QC built into the pipeline, the error rate the old manual process lived with has dropped sharply, and the defects that do occur are caught before they reach a deliverable.
We did not lift the old process into the cloud. We rebuilt it so the only steps left for people are the two that actually need human judgment."
![[ INGEST → PROCESSING → QC → CATALOGUE → ORDERS → DELIVERY → AIRLINE ]](https://mainsiteimgdefault.blob.core.windows.net/images/beam/system-diagram.png) [ INGEST → PROCESSING → QC → CATALOGUE → ORDERS → DELIVERY → AIRLINE ]
[ INGEST → PROCESSING → QC → CATALOGUE → ORDERS → DELIVERY → AIRLINE ]What changed, in seven lines.
Who, with what.
The IFE Media Processing Automation platform replaced a manual, on-premise media supply chain with a cloud-native pipeline on AWS. The project moved the lab from desktop tools, PowerShell scripts, and bespoke per-source workflows to an orchestrated, event-driven platform handling ingest, validation and QC, artifact processing, cataloguing, order fulfilment, and automated multi-channel delivery — with people retained only at the input and output verification points.
Have a media pipeline that still runs by hand?
Bring us in before the manual workflow becomes the bottleneck. We’ll help you map the process, find the highest-friction steps, and build the system around the way your team actually works — not around another generic tool.